Introduction Link to heading
Welcome in the 2nd party of this series, in previous article [Introduction into LLM & Ollama Tool](Local LLMs Part1: Introduction to LLM and Ollama · Journey into IT Knowledge) we focused on short introduction to AI and LLM models their benefits and challenges.
In today article I would like to follow on the challenges which we can have with Public LLM models like ChatGPT or DeepSeek:
- Data Privacy
- Cost
- Confidentiality
- Compliance and Regulations

I will try to summarize in this part how to feed LLMs with your data without loosing privacy and describe their pros and cons of these methods, including when to choose this method.
Common Learning Methods Link to heading
1. Fine-Tuning Link to heading
| Characteristic | Description |
|---|---|
| Definition | Retraining a pre-existing LLM on your custom dataset to adapt it to specific tasks or domains. |
| Pros | Highly effective for domain-specific tasks, results in a more accurate and tailored model, can leverage pre-trained knowledge while adapting to new data. |
| Cons | Requires significant computational resources, time-consuming process, needs expertise in machine learning and access to high-quality datasets. |
| When to Choose | When you need a highly customized model for specific applications, when accuracy and domain-specific performance are crucial, when you have the necessary resources and expertise to fine-tune the model. |
2. Prompt Engineering Link to heading
| Characteristic | Description |
|---|---|
| Definition | The art of creating well-crafted prompts that guide the LLM to produce desired outputs without altering the model itself. |
| Pros | Does not require retraining the model, quick and easy to implement, flexible and can be adjusted on the fly. |
| Cons | Limited by the inherent capabilities of the base model, may not perform as well on highly specialized tasks, can be less consistent compared to fine-tuned models. |
| When to Choose | When you need a quick solution without retraining the model, when dealing with general tasks that do not require extensive customization, when computational resources and time are limited. |
3. In-Context Learning Link to heading
| Characteristic | Description |
|---|---|
| Definition | Providing examples within the prompt to guide the model’s behavior for specific tasks. |
| Pros | No need for model retraining, allows for dynamic adjustment based on the task at hand, can improve performance with relevant examples. |
| Cons | Limited by the number of examples that can be provided within the prompt, effectiveness depends on the quality and relevance of the examples, may require frequent updates and adjustments. |
| When to Choose | When you need to quickly adapt the model to different tasks, when you have relevant examples readily available, when the task does not require extensive retraining. |
4. Retrieval-Augmented Generation (RAG) Link to heading
| Characteristic | Description |
|---|---|
| Definition | Combining information retrieval with generation by allowing the LLM to access external documents or databases to generate more accurate and contextually relevant responses. |
| Pros | Provides up-to-date and relevant information from external sources, enhances the model’s ability to answer specific questions accurately, reduces the need for extensive fine-tuning on large datasets. |
| Cons | Requires setting up and maintaining an external knowledge base or document repository, may introduce latency due to the retrieval process, needs additional components for effective retrieval and integration. |
| When to Choose | When you need the model to access a wide range of up-to-date information, when accuracy and context relevance are critical for the task, when you have the infrastructure to support document retrieval and integration. |
Our Method of Choice Link to heading
I personally prefer Retrieval-Augmented Generation (RAG) and In-Context Learning methods because they provide me the best results and keep my comfort 🛌 at high level.
There is too many ways how you can make RAG process tailored on your needs. The most common ways are by using Python 🐍 tools like LangChain with combination of vector database 📊 (GitHub - chroma-core/chroma: the AI-native open-source embedding database)
However, I am very lazy person and I don’t know much about the whole LLM and AI’s internal workflows at the moment.
Therefore, I decided to use easier way for the moment and use out of box solution AnythingLLM

AnythingLLM is the easiest way to put powerful AI products like OpenAi, GPT-4, LangChain, PineconeDB, ChromaDB, and other services together in a neat package with no fuss to increase your productivity by 100x.
There are also other solutions and methods which can be used as LLM is very trendy topic nowadays 🚀. You may also check solutions like:
- GPT4All
- Open WebUI
- Build Your Own RAG App: A Step-by-Step Guide to Setup LLM locally using Ollama, Python, and ChromaDB - DEV Community
Maybe we will address some of them later. I also want to review RAG with LangChain and Python as it allows you to create your own pipelines.
Technology Stack Link to heading
Okay so, you’ve cut through all that text pile ⚔, we can finally start with deploying our solution with AnythingLLM and Ollama

Installation Link to heading
Installation of Ollama was described already in my previous post Local LLMs Part1: Introduction to LLM and Ollama · Journey into IT Knowledge, and therefore I will not list it here and will continue only with installation and configuration of AnythingLLM.
Installation is very simple:
- Visit their download page Download AnythingLLM for Desktop
- Choose operation system (Windows, MAC or Linux)
- Install
- Done
Note: Your browser show you a warning page as the file is not signed and other AVs can also have an issue to trust to this executable.
Configuration Link to heading
- Disclaimer: Agents functionality is not working with reasoning models like DeepSeek R1.
Once you have AnythingLLM installed, it is very easy to configure it utilize your local LLMs with Ollama.
- Just choose provider Ollama in Search LLM provider window and it will identify you installation automatically:
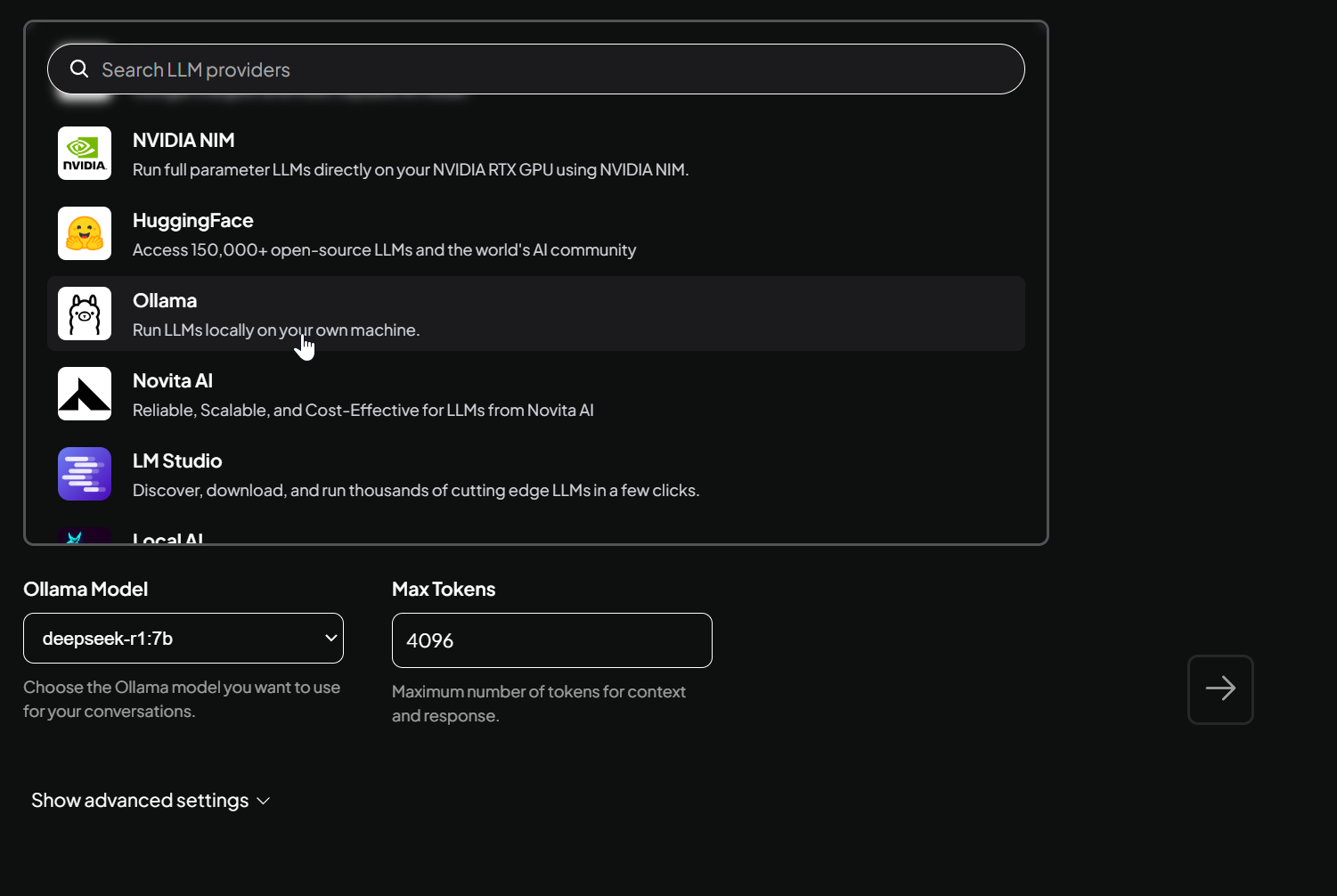

- You may leave advance settings as they are and continue.
- You should see your configuration like:
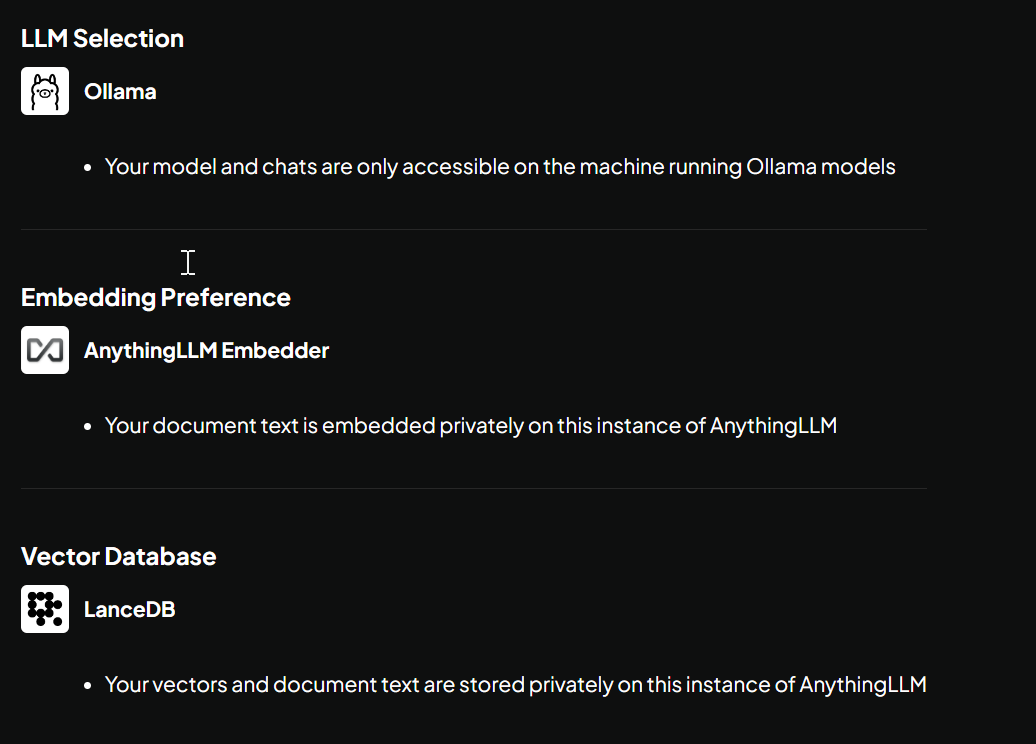
- You can skip survey if you want.
Provide Custom Data Link to heading
Local Data Link to heading
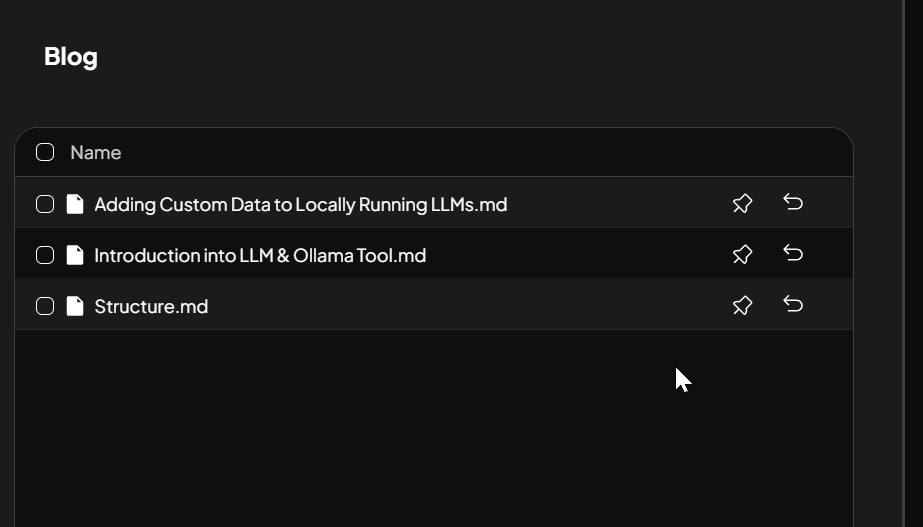
- Create workspace where you will store relevant data/documentation, e.g. “Blog”.
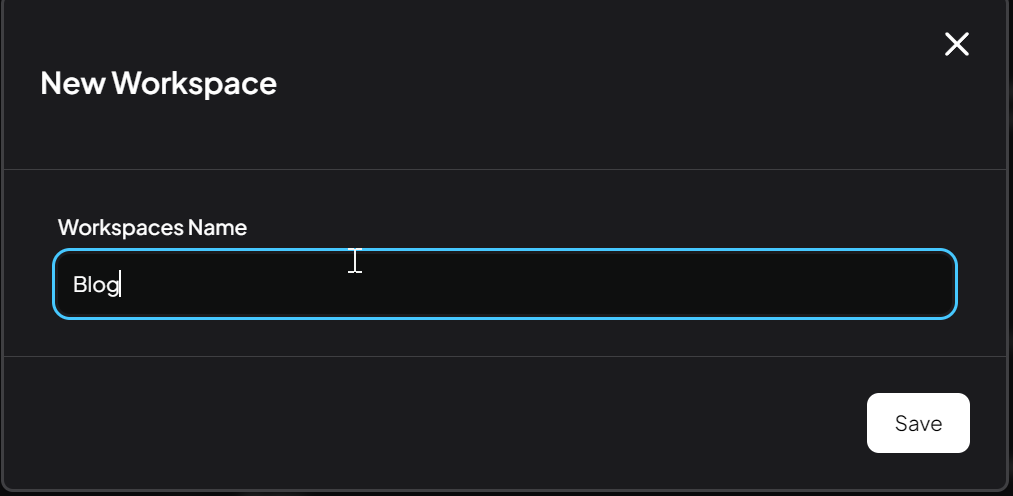
- I don’t know what is optimal way how to organize the data in the Workspaces, but I am creating folders and workspace according to topic which I want to provide to LLM. But I will leave it on everybody to figure out the a way working best for them.
- You can upload your documentation and files by simple clink on upload icon next to name of your workspace
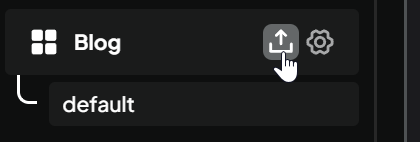
- Then select the files or simply drag and drop them, then click “move to workspace”. They should appear in your workspace:
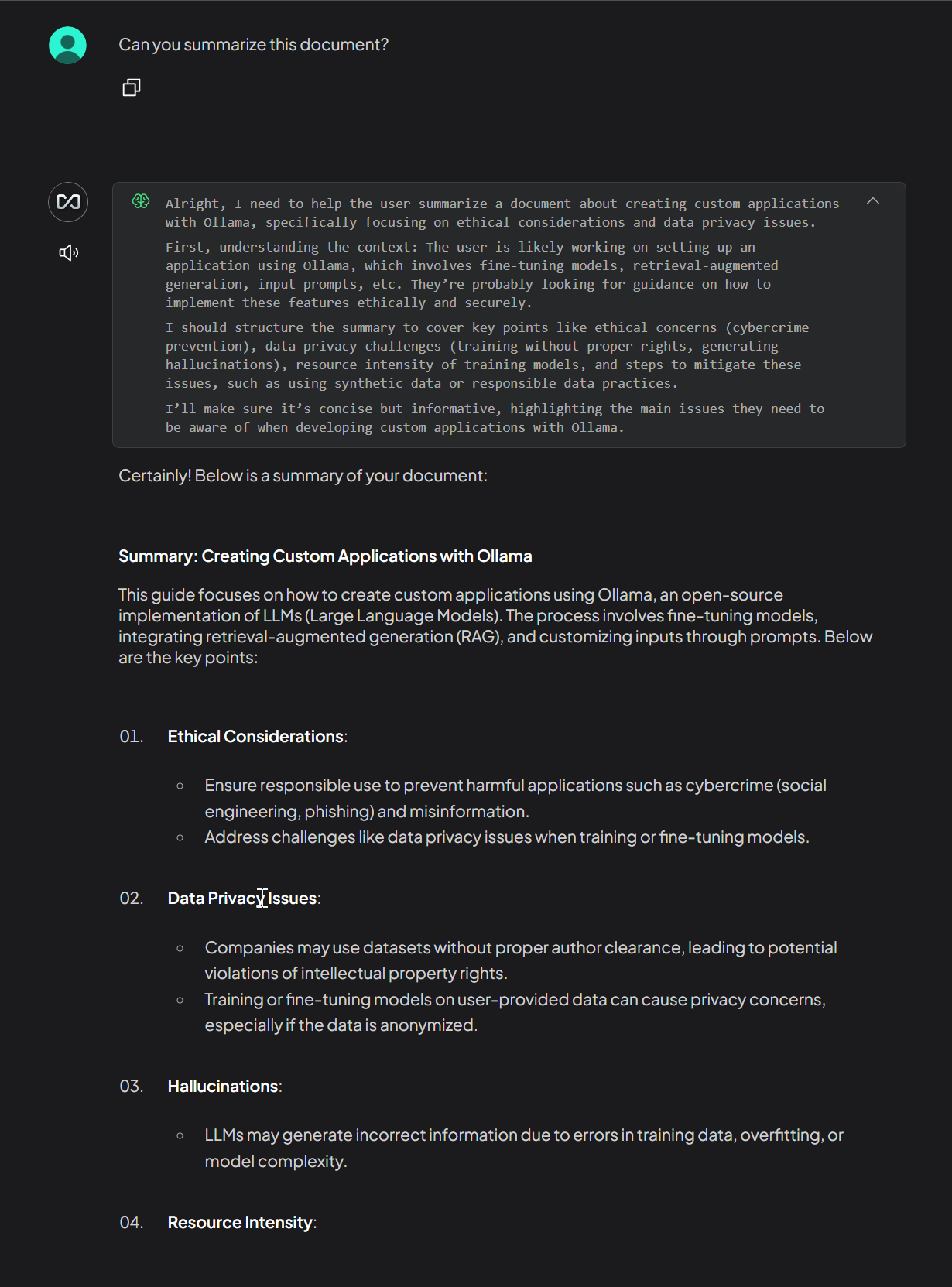
- Simply as anything from your documentation:
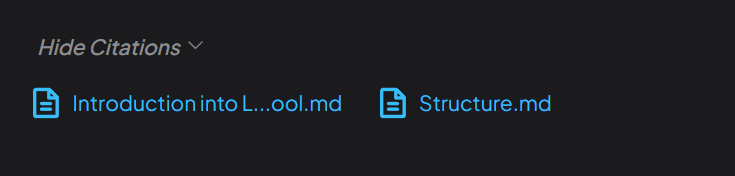
- You may also check from here the LLM take the info:
Remote Data Link to heading
AnythingLLM provide you a possibility to scrap data from Internet site or pull data from repositories (GitHub, GitLab, YouTube transcript) and import them into RAG. Note: For Git solutions, you will need to obtain API key.
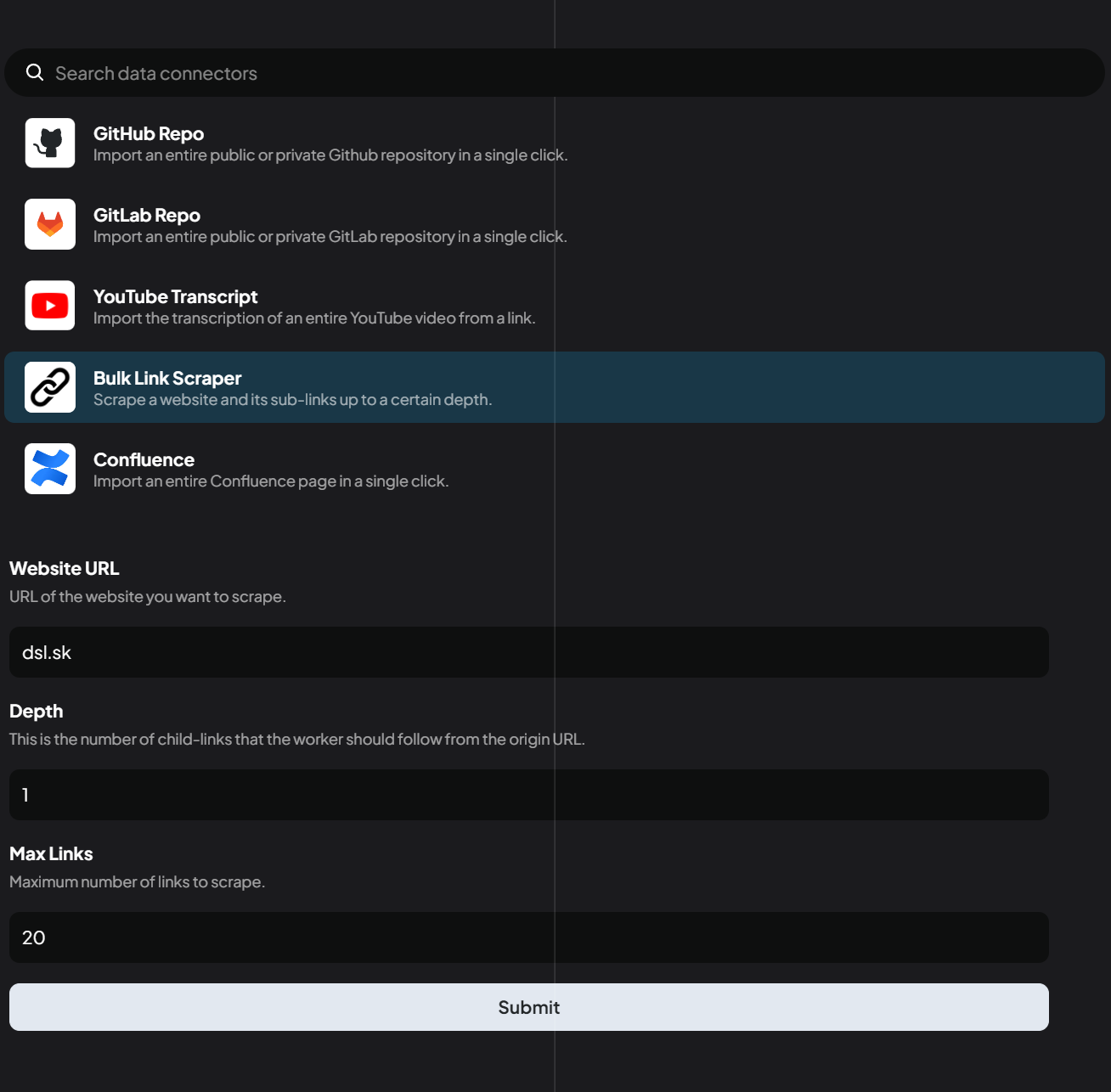
After you scrap the website, it will create you a new folder in Documents section, and you will need to mark it to use in you workspace.
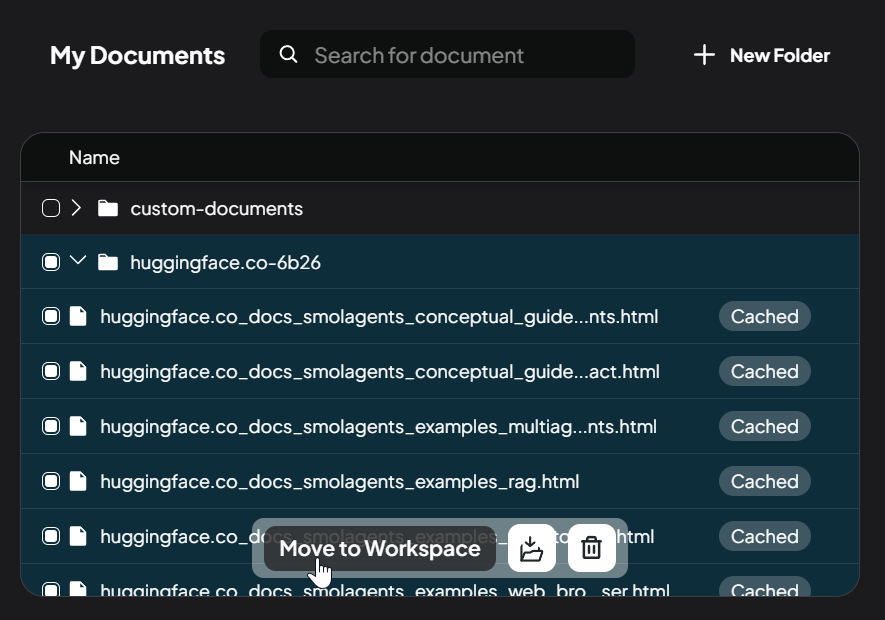
Wualaaa, you can use this documents in your context window (chat) with AI. 🎉🥳
